Next: Likelihood and maximum likelihood Up: A defense of Columbo Previous: AIDS test
A program chooses at random, with equal probability,
![]() or
or ![]() ; then the generator produces a number,
that, rounded to the 7-th decimal digit, is
; then the generator produces a number,
that, rounded to the 7-th decimal digit, is
![]() . The question is, from which random generator
does
. The question is, from which random generator
does ![]() come from?
come from?
At this point,
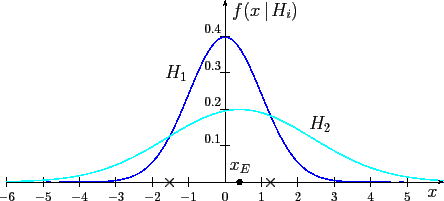
the problem is rather easy to solve, if we know the probability
of each generator to give ![]() . They are54
. They are54
 |
What matters when comparing hypotheses is never,
stated in general terms,
the absolute probability
![]() .
In particular, it doesn't make sense saying
``
.
In particular, it doesn't make sense saying
``
![]() is small because
is small because
![]() is
small''.55
As a consequence, from a consistent probabilistic point
of view, it makes no sense to test a
single, isolated hypothesis, using
`funny arguments',
like how far if
is
small''.55
As a consequence, from a consistent probabilistic point
of view, it makes no sense to test a
single, isolated hypothesis, using
`funny arguments',
like how far if ![]() from the peak of
from the peak of
![]() ,
or how large is the area below
,
or how large is the area below
![]() from
from ![]() to infinity. In particular, if two models
give exactly the same probability to produce an observation,
like the two points indicated by `
to infinity. In particular, if two models
give exactly the same probability to produce an observation,
like the two points indicated by `![]() ' in fig.
9, the evidence provided by
this observation is absolutely irrelevant
[
' in fig.
9, the evidence provided by
this observation is absolutely irrelevant
[
![]() JL
JL![]() `
`![]() '
'![]() ].
].
To get a bit familiar with the weight of evidence in favor of either
hypothesis provided by different observations, the following table,
reporting Bayes factors and JL's due to the integers between ![]() and
and ![]() ,
might be useful.
,
might be useful.
|
|
|
||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
| 0 | |||
|
|
|||
|
|
|||
|
|
|||
|
|
We can check this by a little simulation. We choose
a model, extract 50 random variables and analyze
the data as if we didn't know which generator produced them,
although
considering ![]() and
and ![]() equally likely. We expect
that, as we go on with the extractions, the pieces
of evidence accumulate until we possibly
reach a level of practical certainty.
Obviously, the individual pieces
of evidence do not provide the same
equally likely. We expect
that, as we go on with the extractions, the pieces
of evidence accumulate until we possibly
reach a level of practical certainty.
Obviously, the individual pieces
of evidence do not provide the same ![]() JL, and also the sign
can fluctuate, although we expect more positive contributions
if the points are generated by
JL, and also the sign
can fluctuate, although we expect more positive contributions
if the points are generated by ![]() and the other way around
if they came from
and the other way around
if they came from ![]() .
Therefore, as a function
of the number of extractions the accumulated weight
of evidence follows a kind of asymmetric random walk
(imagine the JL indicator fluctuating
as the simulated experiment goes on, but drifting
`in average'
in one direction).
.
Therefore, as a function
of the number of extractions the accumulated weight
of evidence follows a kind of asymmetric random walk
(imagine the JL indicator fluctuating
as the simulated experiment goes on, but drifting
`in average'
in one direction).
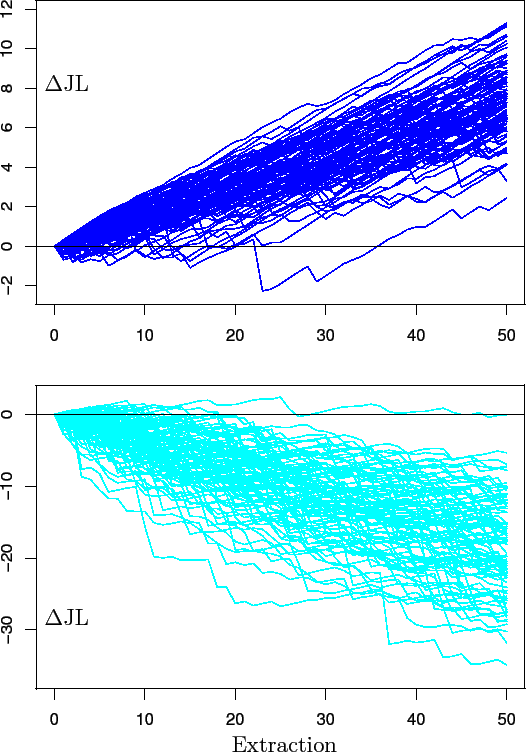 |
Figure 10 shows 200 inferential stories, half per generator. We see that, in general, we get practically sure of the model after a couple of dozens of extractions. But there are also cases in which we need to wait longer before we can feel enough sure on one hypothesis.
It is interesting to remark that the leaning
in favor of each hypothesis grows, in average, linearly with
the number of extractions. That is, a little piece of evidence,
which is in average positive for ![]() and negative for
and negative for ![]() ,
is added after each extraction. However, around the
average trend, there is a large varieties of individual
inferential histories. They all start at
,
is added after each extraction. However, around the
average trend, there is a large varieties of individual
inferential histories. They all start at
![]() JL
JL![]() for
for
![]() , but in practice there are no two identical `trajectories'.
All together they form a kind of `fuzzy band',
whose `effective width' grows also with the number of extractions,
but not linearly. The widths grows as the square root
of
, but in practice there are no two identical `trajectories'.
All together they form a kind of `fuzzy band',
whose `effective width' grows also with the number of extractions,
but not linearly. The widths grows as the square root
of ![]() .56This is the reason why, as
.56This is the reason why, as ![]() increases, the bands tend
to move away from the line
JL
increases, the bands tend
to move away from the line
JL![]() . Nevertheless, individual
trajectories can exhibit very
`irregular'57
behaviors as we can also see in figure
10.
. Nevertheless, individual
trajectories can exhibit very
`irregular'57
behaviors as we can also see in figure
10.
Giulio D'Agostini 2010-09-30