Next: Which generator? Up: A defense of Columbo Previous: Some remarks on the
Imagine an Italian citizen is chosen at random
to undergo an AIDS test. Let us assume
the analysis used to test for HIV infection
is not perfect. In particular, infected people (
HIV)
are declared `positive' (
Pos) with 99.9% probability
and `negative' (
Neg) with 0.1%;
there is, instead, a 0.2% chance
a healthy person
(
![]() ) is told positive
(and 99.8% negative).
) is told positive
(and 99.8% negative).
The other information we need is the prevalence of the virus in Italy, from which we evaluate our initial belief that the randomly chosen person is infect. We take 1/400 or 0.25% (roughly 150 thousands in a population of 60 millions).
To summarize, these are the pieces of information relevant
to work the exercise:52
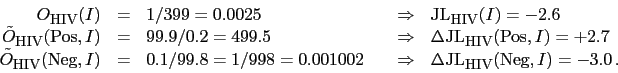
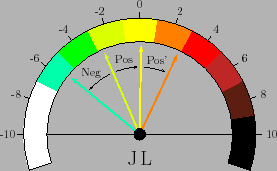
The figure shows also the effect of a second,
independent53analysis, having the same performances of the first one and
in which the person results again positive. As it clear from
the figure, the same conclusion would be reached if only one
test was done on a subject for which a doctor could be in serious
doubt if he/she had AIDS or not (
JL![]() ).
).
From this little example we learn that if we want to have
a good discrimination power of a test, it should have
a ![]() JL very large in module. Absolute discrimination can only
be achieved if the weight of evidence is infinite, i.e. if
either hypothesis is impossible given the observation.
JL very large in module. Absolute discrimination can only
be achieved if the weight of evidence is infinite, i.e. if
either hypothesis is impossible given the observation.
Giulio D'Agostini 2010-09-30