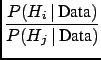Although, to my knowledge, there are not yet specific HEP
applications of these methods, I would like to
give a rough idea of what they are and how they work,
with the help of a simple example. You are visiting some
friends, and, minutes after being in their house,
you sneeze. You know you are allergic to
pollen and to cats,
but it could also be a cold. What is the cause of the sneeze?
Figure ![]() sketches the problem.
sketches the problem.
Then, you see a picture of your friend with a cat. This could be an indication that they have a cat, but it is just an indication. Nevertheless, this indication increases the probability that there is a cat around, and then the probability that the cause of the sneeze is cat's hair allergy increases, while the probability of any other potential cause decreases. If you then establish with certainty the presence of the cat, the cause of the allergy also becomes practically certain.
The idea of Bayesian networks is to build a network of causes and effects. Each event, generally speaking, can be certain or uncertain. When there is a new piece of evidence, this is transmitted to the whole network and all the beliefs are updated. The research activity in this field consists of the most efficient way of doing the calculation, using Bayesian inference, graph theory, and numerical approximations.
If one compares Bayesian networks with other ways of pursuing artificial intelligence their superiority is rather clear: they are close to the natural way of human reasoning, the initial beliefs can be those of experts (avoiding the long training needed to set up, for example, neural networks, unfeasible in practical applications), and they learn by experience as soon as they start to receive evidence[70].