Next: Recap of the section Up: One in thirteen - Previous: Adding pieces of evidence
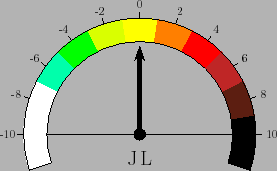
Introducing the new symbol JL, we can rewrite Eq. (21) as
But the judgement is rarely initially unbalanced.
This the role of
JL![]() , that can be considered
as a a kind of initial weight of evidence due to our prior knowledge
about the hypotheses
, that can be considered
as a a kind of initial weight of evidence due to our prior knowledge
about the hypotheses ![]() and
and ![]() [and that could even
be written as
[and that could even
be written as
![]() JL
JL![]() ,
to stress that it is related
to a 0-th piece of evidence]
,
to stress that it is related
to a 0-th piece of evidence]
To understand the rationale behind a possible uniform treatment
of the prior as it would be a piece of evidence,
let us start from a case in which you now
absolutely nothing. For example You have to state
your beliefs on which of my friends, Dino or Paolo,
will first run next Rome marathon. It is absolutely reasonable
you assign to the two hypotheses equal probabilities, i.e. ![]() ,
or
JL
,
or
JL![]() (your judgement is
perfectly balanced). This is because in Your
brain these
names are only possibly related to Italian males. Nothing
more. (But nowadays search engines over the web allow to
modify your opinion in minutes.)
(your judgement is
perfectly balanced). This is because in Your
brain these
names are only possibly related to Italian males. Nothing
more. (But nowadays search engines over the web allow to
modify your opinion in minutes.)
As soon as you deal with real hypotheses of your interest,
things get quite different.
It is in fact very rare the case in which the hypotheses
tell you not more than their names.
It is enough you think at the hypotheses `rain' or `not rain',
the day after you read these lines in the place where you live.
In general the information you have in your brain
related to the hypotheses of your interest can be considered
the initial piece of evidence you have,
usually different from that somebody else
might have
(this the role of ![]() in all our expressions).
It follows that prior odds of 10 (
JL
in all our expressions).
It follows that prior odds of 10 (
JL![]() ) will influence your
leaning
towards one hypothesis, exactly like
unitary odds (
JL
) will influence your
leaning
towards one hypothesis, exactly like
unitary odds (
JL![]() ) followed by a Bayes factor of
10 (
) followed by a Bayes factor of
10 (
![]() JL
JL![]() ).
This the reason they enter on equal foot when
``balancing arguments''
(to use an expression à la Peirce - see the Appendix E)
pro and against hypotheses.
).
This the reason they enter on equal foot when
``balancing arguments''
(to use an expression à la Peirce - see the Appendix E)
pro and against hypotheses.
Finally, table 1 compares judgements leanings, odds and
probabilities, to show that the human sensitivity to belief
(that is something like
Peirce's intensity of belief - see Appendix E)
is not linear with probability.
For example, if we assign
probabilities of 44%, 50% or 56% to events ![]() ,
, ![]() and
and ![]() we do not expect one of them
really more strongly than the others,
in the sense that we are not much
surprised of any of the three occurs. But the same differences
in probability produce quite different sentiment of surprise
if we shift the probability scale (if they were, instead, 1%, 7% and 13%,
we would be highly surprised if
we do not expect one of them
really more strongly than the others,
in the sense that we are not much
surprised of any of the three occurs. But the same differences
in probability produce quite different sentiment of surprise
if we shift the probability scale (if they were, instead, 1%, 7% and 13%,
we would be highly surprised if ![]() occurs).
occurs).
Similarly 99.9% probability on ![]() is substantially different from 99.0%,
although the difference in probability is `only' 0.9%. This is well
understood, and in fact it is known that the best way to express
the perception of probability values very close to 1 is to think to the opposite
hypothesis
is substantially different from 99.0%,
although the difference in probability is `only' 0.9%. This is well
understood, and in fact it is known that the best way to express
the perception of probability values very close to 1 is to think to the opposite
hypothesis
![]() , that is 0.1% probable in the first case and 1%
probable in the second - we could be quite differently surprised
if
, that is 0.1% probable in the first case and 1%
probable in the second - we could be quite differently surprised
if ![]() does not result to be true in the two cases!16
does not result to be true in the two cases!16
From the table we can see that the human resolution is about 1/10
of the JL,
although this does not imply that a probability value of
53.85% (
JL![]() ) cannot be stated. It all depends
how this value has been evaluated and what is the purpose of
it.17
) cannot be stated. It all depends
how this value has been evaluated and what is the purpose of
it.17
Giulio D'Agostini 2010-09-30
![$\displaystyle \sum_{k=1}^n \log_{10}[\tilde O_{i,j}(E_k,I)] + \log_{10}[O_{i,j}(I)]\,,$](img129.png)
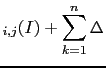 JL
JL![$\displaystyle \log_{10}\left[\tilde O_{i,j}(E_k,I)\right]$](img139.png)