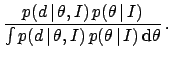Posterior probability distributions provide the full description of our state of knowledge about the value of the quantity. In fact, they allow to calculate all probability intervals of interest. Such intervals are also called credible intervals (at a specified level of probability, for example 95%) or confidence intervals (at a specified level of 'confidence', i.e. of probability). However, the latter expression could be confused with frequentistic 'confidence intervals', that are not probabilistic statements about uncertain variables (D'Agostini 1999c).
It is often desirable to characterize the
distribution in terms of a few numbers. For example,
mean value (arithmetic average) of the posterior,
or its most probable value (the mode)
of the posterior, also known as the maximum a
posteriori (MAP) estimate.
The spread of the distribution is often
described in terms of its standard deviation
(square root of the variance).
It is useful to associate the terms mean value and standard deviation with
the more inferential terms expected value,
or simply expectation (value),
indicated by ![]() , and
standard uncertainty (ISO 1993), indicated by
, and
standard uncertainty (ISO 1993), indicated by ![]() , where the
argument is the uncertain variable of interest.
This will be our standard way of reporting the result of
inference in a quantitative way, though, we emphasize
that the full answer is given by the posterior distribution,
and reporting only these summaries
in case of the complex distributions
(e.g. multimodal and/or asymmetrical pdf's)
can be misleading, because people tend to think of a
Gaussian model if no further information is provided.
, where the
argument is the uncertain variable of interest.
This will be our standard way of reporting the result of
inference in a quantitative way, though, we emphasize
that the full answer is given by the posterior distribution,
and reporting only these summaries
in case of the complex distributions
(e.g. multimodal and/or asymmetrical pdf's)
can be misleading, because people tend to think of a
Gaussian model if no further information is provided.