Next: Estimating the proportion of Up: Rough reasoning based on Previous: Fraction of sampled positives Contents
The reason of these counter-intuitive results is due to the role of the prior probability of being infected or not, based on the best knowledge of the proportion of infected individuals in the entire population.8The easy explanation is that, given the numbers we are playing with, the number of positives is strongly `polluted' by the large background of not infected individuals.
In order to see how the outcomes depend on ![]() , let us lower
its value from 10% to 1%.
In this case our expectation will be of 1286 positives, out of which
only 98 infected and 1188 not infected (the details are left
as exercise).
The fraction of positives really infected becomes now only 7.6 %.
On the other hand the fraction of negatives really
not infected is as high as 99.98 %.
Figure
, let us lower
its value from 10% to 1%.
In this case our expectation will be of 1286 positives, out of which
only 98 infected and 1188 not infected (the details are left
as exercise).
The fraction of positives really infected becomes now only 7.6 %.
On the other hand the fraction of negatives really
not infected is as high as 99.98 %.
Figure ![[*]](crossref.png)
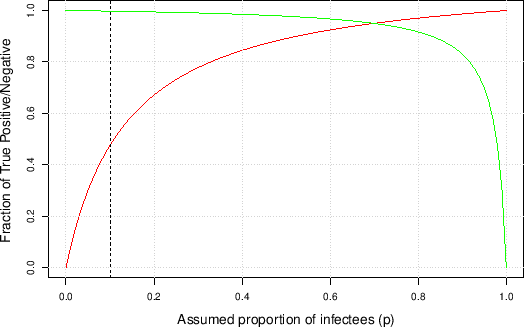 |
This should make definitively clear that
the probabilities of interest
not only depend, as trivially expected,
on the performances of the test, summarized here by
![]() and
and ![]() , but also - and quite strongly! -
on the assumed proportion of infectees in the population.
More precisely, they depend on whether
the individual shows symptoms possibly related to the
searched for infection and on the probability that the same symptoms
could arise from other diseases. However
we are not in the condition to
enter into such `details' in this paper and shall
focus on random samples of the population.
Therefore, up to Sec , in which
we deal with the probability that a tested individual
is infected or not on the basis of the test result, we shall refer
to
, but also - and quite strongly! -
on the assumed proportion of infectees in the population.
More precisely, they depend on whether
the individual shows symptoms possibly related to the
searched for infection and on the probability that the same symptoms
could arise from other diseases. However
we are not in the condition to
enter into such `details' in this paper and shall
focus on random samples of the population.
Therefore, up to Sec , in which
we deal with the probability that a tested individual
is infected or not on the basis of the test result, we shall refer
to ![]() as `proportion of infectees' in the population.
But everything we are going to say is valid as well if
as `proportion of infectees' in the population.
But everything we are going to say is valid as well if
![]() is our `prior' probability that a particular individual is
infected, based on our best knowledge of the case.
is our `prior' probability that a particular individual is
infected, based on our best knowledge of the case.