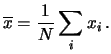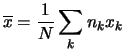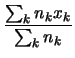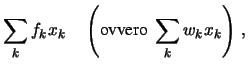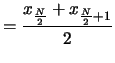Se i dati sperimentali sono stati raggruppati senza unire classi elementari adiacenti è facile dimostrare che i due valori della media ottenuti dalle (5.6) e (5.7-5.8) sono esattamente uguali (è una semplice applicazione della proprietà commutativa e associativa della somma). Nel caso contrario essi sono soltanto approssimativamente uguali. L'approssimazione è tanto migliore quanto più grande è il numero di classi e quanto più regolarmente sono distribuiti i valori dei dati originali all'interno delle classi.
Per come è definita la media, può capitare che il suo valore numerico non coincida con nessuno dei valori dei dati sperimentali. Quindi ``medio'' non va inteso come quello che si verifica di più, ma semplicemente ...come medio5.3.
Ci sono casi in cui si è effettivamente interessati ai valori che capitano più frequentemente. Si introduce allora il concetto di moda come il valore che si verifica più spesso, ovvero quello che ha peso statistico maggiore o, per dirlo in altri termini, ``quello che va più di moda''. Per come è definita si capisce che la moda può essere non unica. Si parla allora di distribuzione multimodale. Nei dati di conteggio per 3 e 30 secondi la moda vale rispettivamente 0 e 4.
Un altro modo per indicare la posizione di una distribuzione è di considerare il valore centrale - mediano - nel senso del valore rispetto al quale ci siano tanti valori più grandi quanti valori più piccoli. Tale valore è chiamato mediana. Per trovarlo si ordinano prima i dati e poi:
Le tre misure di posizioni introdotte non sono utilizzate una in alternativa dell'altra, anzi molto spesso la conoscenza simultanea delle tre fornisce delle utili informazioni sulla distribuzione. Per esempio si immagini tre comunità il cui reddito medio sia di 1000$ l'anno, ma i cui valori di moda e mediana siano:
Anche se sono state introdotte per completezza, la moda e la mediana, utili per molte applicazione di statistica descrittiva, in questo testo faremo uso soltanto della media.