Next: Inferring from the observed Up: Measurability of Previous: Resolution power Contents
![[*]](crossref.png) for
for
Now it is interesting to know how much uncertain this number is.
One could improperly use a quadratic
combination of the two standard uncertainties, thus getting
![]() . But this evaluation of the uncertainty
on the difference
is incorrect because
. But this evaluation of the uncertainty
on the difference
is incorrect because ![]() and
and ![]() are obtained from the same knowledge of
are obtained from the same knowledge of ![]() and
and ![]() , and
are therefore correlated. Indeed, in the limit of
negligible uncertainties on these two parameters,
the expectations would be much more precise, as we can see from the
upper plot of Fig. ,
with a consequent reduction of
, and
are therefore correlated. Indeed, in the limit of
negligible uncertainties on these two parameters,
the expectations would be much more precise, as we can see from the
upper plot of Fig. ,
with a consequent reduction of
![]() .
These are the results, obtained by Monte Carlo evaluation using only R commands
(see script in Appendix B.8),43with one extra digit
with respect to Fig.
and adding
also the correlation coefficient:
.
These are the results, obtained by Monte Carlo evaluation using only R commands
(see script in Appendix B.8),43with one extra digit
with respect to Fig.
and adding
also the correlation coefficient:
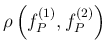 |
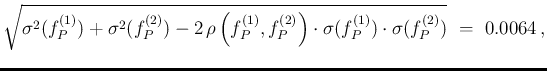 |
An important consequence of the correlation among the predictions of
the numbers of positives in different populations
is that we have to expect a similar correlation in the
inference of the proportion of infectees in different populations.
This implies that we can measure their difference
much better than how we can measure a single proportion.
And, if one of the two proportions is precisely known
using a different kind of test, we can take its value
as kind of calibration point, which will allow
a better determination also of the other proportion.
We shall return to this interesting point in Sec. .