Which priors?
After having read in the first part of the paper
the dramatic role of the prior, when we
had to evaluate the probability of individual
being infected, given the test result,
one might be surprised by the regular use of
a flat prior of 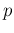 throughout the present section.
First at all, we would like to point out that we are
doing so, in this case, not
“in order to leave the data to `speak' by themselves”,
as someone says. It is, instead, the other way
around: the values of preferred by the data,
starting from a uniform prior, are characterized
by a distribution much narrower than what we
could reasonably judge, based on previous rational knowledge.
In other words,
they are not at odds with what we could believe
independently of the data. But this is not always the case,
and experts could have more precise expectation,
grounded on their knowledge.
throughout the present section.
First at all, we would like to point out that we are
doing so, in this case, not
“in order to leave the data to `speak' by themselves”,
as someone says. It is, instead, the other way
around: the values of preferred by the data,
starting from a uniform prior, are characterized
by a distribution much narrower than what we
could reasonably judge, based on previous rational knowledge.
In other words,
they are not at odds with what we could believe
independently of the data. But this is not always the case,
and experts could have more precise expectation,
grounded on their knowledge.
Anyway, a prior distribution is something
that we have to plug in the
model, if we want to perform a probabilistic inference.
In practice - and let us remind again that
“probability is good sense reduced to a calculus” -
we model the prior in a reasonable and mathematically
convenient way, and the Beta distribution is well suited
for this case, also due to the flexibility of the shapes
that it can assume, as seen in Sec. ![[*]](crossref.png) .
Once we have opted for a Beta, a uniform prior is recovered
for
.
Once we have opted for a Beta, a uniform prior is recovered
for 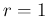 and
and 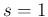 , although we are far from
thinking that
, although we are far from
thinking that
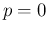 or
or 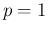 are possible, as well as that
could be above 0.9 with 10% chance, and so on.
are possible, as well as that
could be above 0.9 with 10% chance, and so on.
Subsections