Next: Sceptical combination with JAGS Up: Probabilistic combination achieved by Previous: Gibbs sampling in the
model {
for (i in 1:length(d)) {
d[i] ~ dnorm(m, 1/s[i]^2);
}
m ~ dnorm(0.0, 1.0E-8);
}
The loop is just the implementation of the graphical model
on the right side of Fig. 5, with
First we assign the experimental values to the vector d and
s (no declarations are required in R) and then we
evaluate
and print the weighed average and the combined standard deviation
calculated from Eqs. (1) and (2):
d <- c(493.691, 493.657, 493.670, 493.640, 493.636, 493.696)
s <- c( 0.040, 0.020, 0.029, 0.054, 0.011, 0.007)
d.av <- sum(d/s^2)/sum(1/s^2)
s.av <- 1/sqrt(sum(1/s^2))
cat(sprintf("combined value: %f +- %f\n", d.av, s.av))
Executing the script16containing these five lines, we get
combined value: 493.676599 +- 0.005478that for the moment is just a check.
Let us now move to the rjags stuff in the R script:
library(rjags) # load rjags
data <- NULL # declare an empty list
data$d <- d # first element of the list
data$s <- s # second element of the list
model <- "weighted_average.bug"
jm <- jags.model(model, data) # define the model
update(jm, 100) # burn in
chain <- coda.samples(jm, c("m"), n.iter=10000) # sampling
So, first the package rjags is loaded
calling the function library(), then we fill the data
in the list17 data (arbitrary name) and
we put the model file name into
the string variable model (again arbitrary name). Finally
we interact with JAGS in three steps:
Compiling model graph Resolving undeclared variables Allocating nodes Graph information: Observed stochastic nodes: 6 Unobserved stochastic nodes: 1 Total graph size: 29
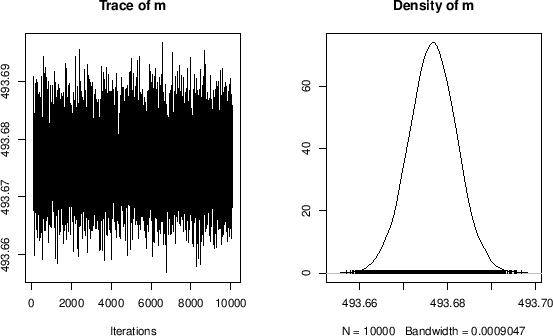
R provides also a summary of the result, using the
function summary(chain) ![]() or, better,
print(summary(chain)) if we want to include it into a script
or, better,
print(summary(chain)) if we want to include it into a script![]() ,
with many statistical informations like average,
standard deviation and quantiles
for each sampled variable.
Or we can do it in more detail using the high level
R functions.
Here is, for example, how to calculate mean and standard deviation
(also to show a way to extract the history
of a single variable from the object returned by coda.samples()):
,
with many statistical informations like average,
standard deviation and quantiles
for each sampled variable.
Or we can do it in more detail using the high level
R functions.
Here is, for example, how to calculate mean and standard deviation
(also to show a way to extract the history
of a single variable from the object returned by coda.samples()):
m.mean <- mean(chain[[1]][,'m'])
m.sd <- sd(chain[[1]][,'m'])
cat(sprintf("JAGS result: %f +- %f\n", m.mean, m.sd))
resulting (with this particular sampling) in
JAGS result: 493.676632 +- 0.005451practically identical to the weighted average obtained using exact formulae.